Adam
Wed winners- Maryland and PSU
Thur winners- MSU, UW, OSU, PSU
Fri winners- Purdue, UW, ILL, Neb
Sat winners- Purdue, ILL
Champion- ILL
Adam
Wed winners- Maryland and PSU
Thur winners- MSU, UW, OSU, PSU
Fri winners- Purdue, UW, ILL, Neb
Sat winners- Purdue, ILL
Champion- ILL
Here they are Torvik:
Wed- Neb over Minn, UW over OSU
Thur- Mich over Rutgers, Iowa over UW, Illinois over PSU, Neb over Maryland
Fri- Purdue over Mich, Iowa over MSU, Illinois over NW, Indiana over Neb
Sat- Purdue over Iowa, Indiana over Illinois
Sun- Purdue over Indiana
I don’t remember the last time I blogged about football, but with the Fickell hire it seemed like a good idea to post some thoughts. If for no other reason than so that Torvik can throw it back in my face in 10 years when I’m wrong.
First, I didn’t like how Chryst went out. I don’t know (and
I don’t think anyone else does either) what went down between Chryst and McIntosh,
but it doesn’t sit well. He averaged 9 wins a year and should have had a chance
to turn the season around. Good guy, good coach, got a raw deal at the end. It’s
entirely possible the criticism of Chryst is valid, and the program was going
downhill. The recruiting department took some hits, the offense was bad again, Chryst
seemed to struggle with diving into NIL and the dirty business this will entail
for college programs here on out. Still, he had a formula that worked at UW and
I think he would have continued rolling out 9 wins a year for the next decade
given the chance. We’ll never know what that universe would have looked like, nor
the one where Jimmy Leonard took over the program, nor the one where Chryst was
fired last year and replaced with Leonard like many wanted. So what are we looking
at. I’ll draw up 3 possibilities and what I think of each.
2) Fickell takes WI straight into the tank. This is the horror scenario, and I think we narrowly avoided this already when Gary Anderson left us (thank God). If you think this can’t happen just look at what happened to MI between Carr and Harbaugh, or look at Nebraska today (one of the most storied programs in college football with rabid fans, great facilities, and solid recruiting). That could be us. Fickell could be our RichRod changing the scheme, changing the recruiting, and losing an already fickle and quick to bail fan base. If it goes this way it may never come back. Barry was a great but also lucky hire. Other than Fickell, no other hot coach in demand has wanted this job despite 2 recent openings when Anderson and Chryst were hired. If the program tanks, it will take another Barry to resurrect it, and those guys are hard to come by. Chance of this scenario less than 20%.
3) Fickell spends the next 6-9 years at UW and wins about 9 games a year. He has a couple years where we overperform and make it into an expanded playoff with 11-12 wins, and a few years we underperform and barely make a bowl game. Sound familiar? It should because this is what we are. We won’t get to the next level because of recruiting. Fickell said in his press conference we will recruit “within the 300 mile radius”. That’s because almost all kids stay within that range of home when picking a school. We just don’t have enough 4 and 5 star kids within 300 miles to compete with schools in Ohio, Florida, Texas, etc. that have 10 times what we have right next to home. We will bring in 3 star kids, we will develop them, we will get some special kids here and there that take us to double digit wins. That won’t sustain a championship level program though year in and year out, you just need more 4 and 5 star kids that live nearby, and we just don’t have that. Chance of this scenario- greater than 75%.
Chorlton, it's that time again. Time for me to embarrass you by picking the rest of the Big Ten tournament.
Yes, we forgot about Wednesday. But Wednesday is the play-in day. Those games don't count.
Here we go - get your picks in or lose by default. I've spent no time thinking about this, so I'm about to intuit the future.
THURSDAY
Indiana over Michigan
MSU over Maryland
Iowa over Northwestern
Ohio St. over Penn St.
FRIDAY
Indiana over Illinois
MSU over Wisconsin
Purdue over Ohio St.
Iowa over Rutgers
SATURDAY
Iowa over Indiana
Purdue over MSU
SUNDAY
Purdue over Iowa
It's February, so bracketologizing and bubble watching are getting into high gear. (If you're keeping track, it's the fourth-most wonderful time of the year according to my seasonal analytics.)
One of the more interesting résumés at the moment is North Carolina's. For the most part, UNC looks like a team that is directly on the bubble:


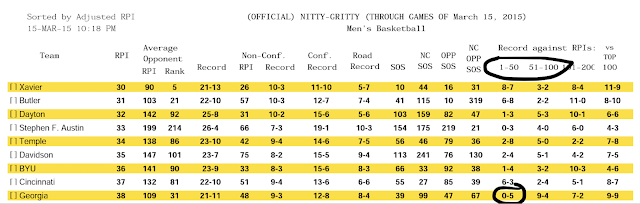
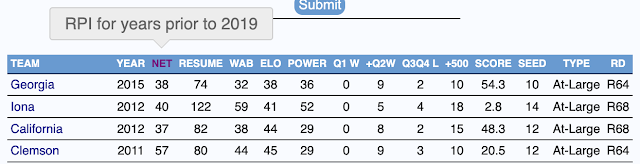
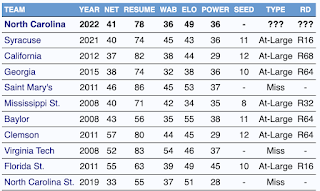
The 2 foul auto-bench
I have frequently seen criticism of the 2 foul auto-bench strategy
recently. I’m not a complete believer in the auto-bench in 100% of
circumstances, but I certainly understand why a coach would do it. It feels to
me like the argument against the 2 foul auto-bench has become like the argument
for fouling when up 3 at the end of the game, in that people argue that it is clearly
they best strategy when it’s not clear that it is. They also seem to ignore all
the good reasons to bench the guy, and assume nothing bad will happen. They seem
to think the player will get their normal minutes and be their normal
productive selves with the 2 fouls, and even if they get a 3rd, they
are still unlikely to foul out. If this were true, it would be a no brainer to
leave the player in with 2 fouls, but here are some considerations as to why
this is not always the case.
1) If a player has 2 fouls, they can’t really play
defense well, because they have to protect themselves. Most often the auto-bench
criticism comes when a good offensive player is sat down because the team needs
his scoring. This ignores the fact that the gains in offense by keeping him on
the court are offset by worse defense because they can’t play the defensive
scheme correctly in order to not risk the 3rd foul. This is compounded
in the team defense because the other players on the court can’t count on the 2
foul player to do what the system dictates they should do, and can put every
other defender on the court in bad positions.
2)
Auto-benching is a tool to teach the player and
the team not to foul. Coaches don’t coach to win 4 minute segments, they coach
to win games and championships. If you have a defensive system that is based on
not fouling, you can’t tolerate players racking up 2 fouls each half. Fouling puts
other team in the bonus and makes your other fouls hurt more. Many teams
defensive scheme is based on minimizing fouls at the expense of ball pressure,
creating turnovers, etc. If this is your philosophy, then you can’t tolerate
players fouling 2 times in a half. A great coach once said, “Coaching is more
about what you accept than what you say”.
3)
Sometimes a player committing fouls too frequently
just isn’t playing all that well. If they’re not moving their feet in the first
10 minutes, why would a coach think that is going to change in the next 10. If
a player is shooting poorly, is 0-5, and coach sits him to think for a bit, you
don’t hear the same criticism as a coach benching with 2 fouls because a player
is playing defense with his hands instead of his feet.
Here are some other short considerations that play heavy
into the decision to bench the 2 foul player:
1)
Can you protect him? Can you stick him in the
corner in a zone, or put him on a non-offensive threat in man to man?
2)
Does your team play pressure on the ball? If so,
can you do so with this player on the court?
3)
Who are you coaching against? Are they a coach
that will recognize the matchup and can use iso on the wing or on the block
against them, or put the player in a pick and roll defense?
4)
Is it a player that commits a lot of fouls, or
someone that is not a fouler?
5)
Are you playing a team that draws a lot of fouls?
6)
Are you up or down a significant number of
points, and who is your opponent? Are they way better than you or way worse? Do
you need the player on the floor to compete?
7)
Who are the refs, and are they calling tons of
ticky tack fouls, or are the letting everyone play?
8)
Players that just got called for a foul are often
frustrated. Frustrated players seem to be more likely to commit another foul. (just
seems that way to me anyway)
I’m not an auto-bench lover myself, but I would like to hear
some of these considerations talked about when the auto-bench comes up. Seems
like the issue is over simplified. Too many assume that the low risk of a 3rd
foul is the only possible problem when leaving them on the court, when in fact there
are many other factors to consider.